数据结构之排序:希尔排序
本文共 1261 字,大约阅读时间需要 4 分钟。
直接插入排序算法简单,在n值较小时,效率比较高;当n值比较大师,如果待排序序列是按关键字值基本有序,效率依然很高,可以提高到 O(n) 。希尔排序正式从这两点出发对直接插入排序的改进方法。
希尔排序(Shell Sort)又称为“缩小增量排序”,有D. L. Shell在1959年首先提出来。
基本思想
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量 dt=1(dt-1<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。该方法实质上是一种分组插入方法。
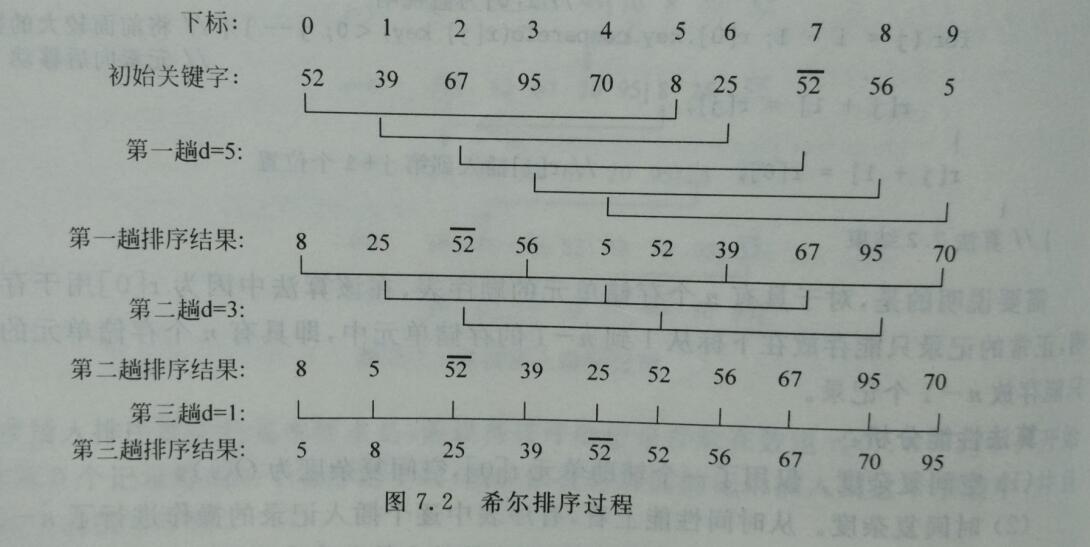
主要步骤
- 选择一个增量序列{d0, d1, … ,dk-1}
- 根据当前增量di将n条记录分成di个子表,每个子表中记录的下标相隔为di
- 对各个子表中的记录进行直接插入排序
- 令i=0,1,…,k-1,重复2-4
性能
空间复杂度:与直接插入排序一样为 O(1) 。
时间复杂度:时间效率依赖于增量序列的选取。最好的情况为 O(n) ,最坏的情况为 O(n2) 。使用Hibbard增量序列时{
2k−1,2k−1−1,...,7,3,1 },时间复杂度为 O(n2/3) 。稳定性:是不稳定的排序算法。
java代码实现:
/** * 希尔排序,O(n2) * 使用shell增量,h(max)=n/2,h(k)=h(k+1)/2; * Hibbard增量(1, 3, 7, .......2k - 1)的希尔排序的时间复杂度为O(N3/2) * @param arr * @return */ public static> void shellSort(T[] arr) { T tmp = null; int size = arr.length; int gap, i, j; for (gap = size / 2; gap > 0; gap /= 2) { for (i = gap; i < size; i++) { tmp = arr[i]; for (j = i; j >= gap && tmp.compareTo(arr[j - gap]) < 0; j -= gap) { arr[j] = arr[j - gap]; } arr[j] = tmp; } } }
参考:
1. 刘小晶,数据结构——Java语言描述(第2版),清华大学出版社 2. MARK A W, 数据结构与算法分析: Java 语言描述,机械工业出版社
你可能感兴趣的文章
【Vuetify】基础(二)
查看>>
JMeter-Web request
查看>>
Hive SQL报错:SemanticException [Error 10004]: Invalid table alias or column reference
查看>>
Hive SQL踩坑记录-NULL判断、字符串拼接、执行报错:Expression not in GROUP BY key
查看>>
【Hive SQL】使用正则表达式做数据清洗
查看>>
学习笔记-集合框架
查看>>
学习笔记-散列表
查看>>
学习笔记-Map映射
查看>>
学习笔记-面向对象思想
查看>>
学习笔记-Java swing
查看>>
单元测试-生成Junit测试类
查看>>
POST编程代码实现
查看>>
关于【端口号被占用的问题的解决办法】
查看>>
FFmpeg视频剪辑拼接
查看>>
简单封装Http的Get和Post请求
查看>>
利用Lambda解决蓝桥杯【消除尾一】问题
查看>>
由size_t引发的思考
查看>>
QT水费管理系统 ——纯C++开发
查看>>
PHP调用科大讯飞语音服务
查看>>
mui.ajax使用注意事项
查看>>